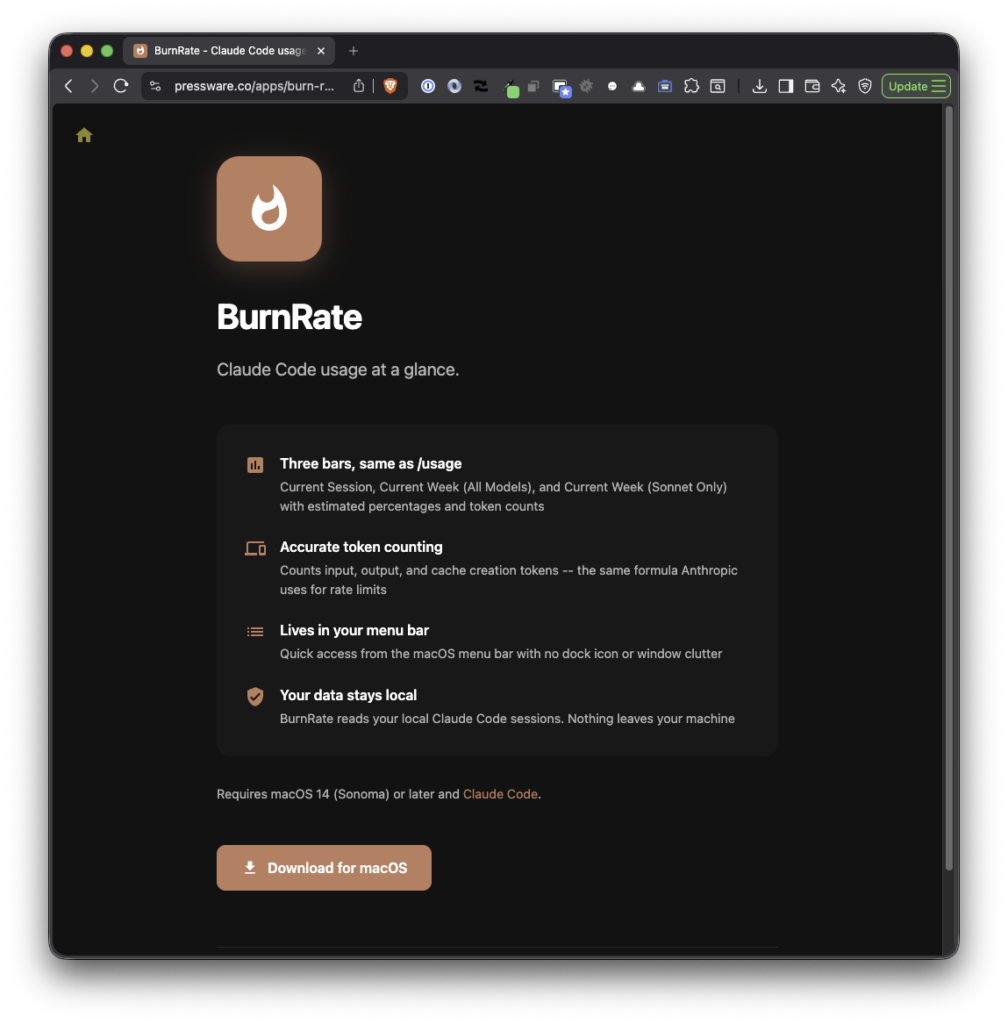
A few months ago I shipped the first version of BurnRate (and another version after that). It’s a macOS menu bar app that showed your Claude Code usage limits at a glance.
It solved a real problem: I didn’t want to stop what I was doing to type /usage every time I wondered how close I was to hitting my limits.
The first version of Now Playing Notify was primarily focus on notifications for the currently playing track. The second release was about being able to do something with them such as being able to click to open a track, copy a link, and launch at login.
This release is focused more on optimizing several things behind the scenes. As such, most of what’s in 1.2.0 is invisible.
Where Can I Watch? 1.3.0 is out, and this one is less about new features and more about making controls that have been in the app since launch easier to find and easier to trust.
When 1.2.0 shipped, I wrote that 1.3.0 was going to be a detail-page overhaul. But the more I used the app, the more I noticed another set of issues specifically around the filtering controls in the Services tab. They’ve been there since 1.0.0, but they’re buried far too low beneath the list of streaming service providers. So I shifted gears. The detail-page work moved to 1.4.0, and 1.3.0 became a clarity pass on the filtering experience across Search and Trending.
If you spend any meaningful amount of time working with Claude Code, you’ll eventually hit a familiar wall: you open a conversation, ask it to do something, and it starts poking around your project like it’s never been there before.
Because it hasn’t. Every conversation starts fresh.
That’s fine for small projects. But when you’re working across a monorepo with a dozen cloud functions, shared utilities, and deployment scripts, watching Claude re-explore the same directory tree for the fifth time in yet-another-worktree in a single day, it gets old (and expensive, as far as tokens are concerned).
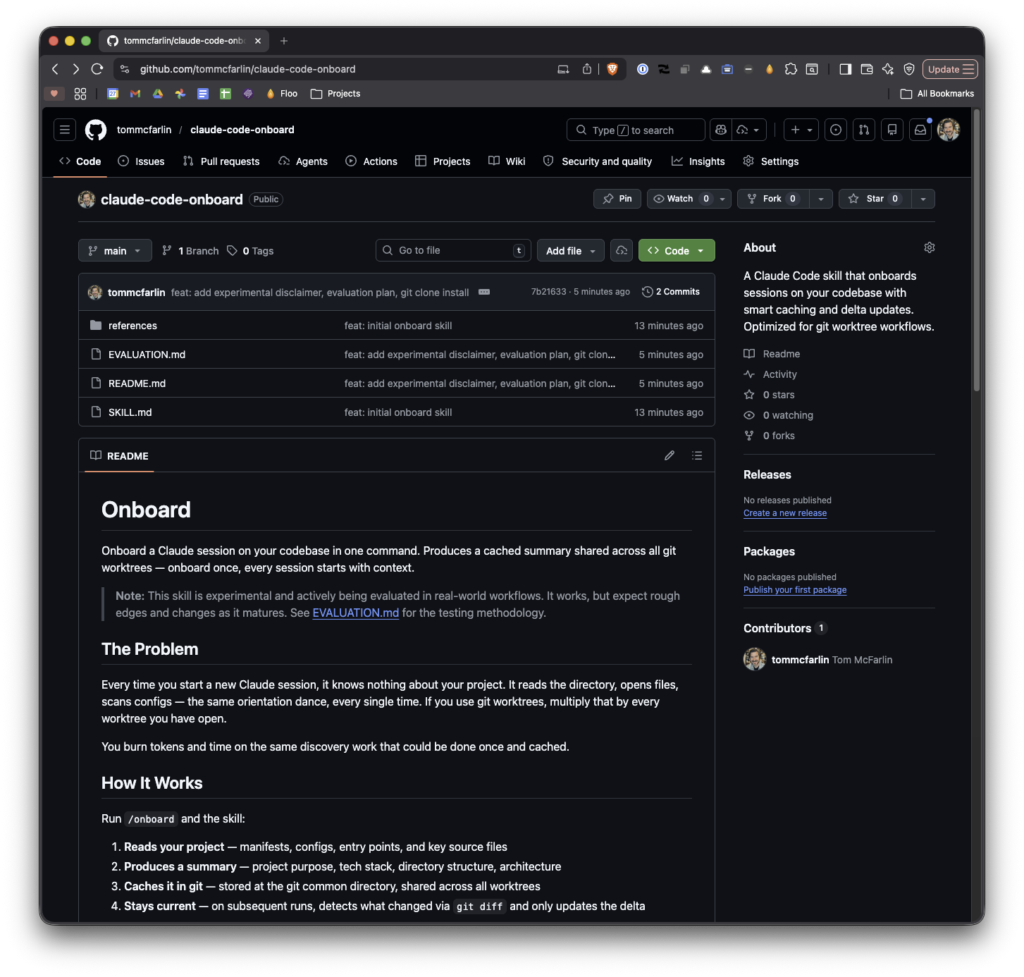
So I built /onboard. It’s a Claude Code skill that scans the current working directory, builds a structured summary of the codebase, and caches it so future conversations can skip the discovery phase entirely.
It started life as a slash command called /ingest, but I’ve since ported it to a proper skill with smarter defaults and a key-files-first approach that keeps token costs down.
Granted, it’s very much experimental right now (so much so I’m documenting the process of evaluating it).
I wrote this plugin a few years ago to scratch a personal itch: those red notification badges in the WordPress admin menu were more annoying than not while I was trying to focus on other things. (I knew I had updates to complete but I do them on my own schedule and didn’t want the visual noise whenever I was working on something else.)
The original version was a single-file plugin that got the job done, but only good enough. It worked by hiding badges with JavaScript after the page loaded, which meant you’d see them flash for a split second on every page. The toggle was a site-wide option, so if one admin muted notifications, every admin lost them. And the AJAX call used GET for a state-changing action, which was more of a quick hack to get it working than anything else.
So I rebuilt it from scratch. This is version 2.0.0.
Kinsta offers premium managed WordPress hosting for everyone, small or large. Powered by Google Platform and strengthened by Cloudflare, they take performance to the next level. All hosting plans include 24/7/365 support from their team of WordPress engineers. Get startedwith a free migration today.