If you spend any meaningful amount of time working with Claude Code, you’ve likely noticed it doesn’t actually know what time it is beyond when you start the initial session.
It knows the date, more or less. But ask it to reason about “this morning” versus “last night,” or how long a build has been running, or whether it’s even the same day you started, and you’ll watch it guess. So you do what I did for weeks: you open a message with “it’s Thursday at 9am Eastern” just to give it its bearings.
At the end of each year, I’ve usually written a “most popular articles of the year” type of article. Last year, however, I wrote a slightly longer “year in review” type of post. Given that we’re at the end of another year and I enjoyed writing about 2024, I thought it worth the time to do another one for 2025.
For the most part, I’m sticking with the same format as last year covering what I’ve read, listened to, and how I did with some of my other goals. I’m also adding a couple of sections related both to work and other projects that I completed (or at least started) this year.
Highlights of 2025
Work
I don’t talk much about my day-to-day here and haven’t so far as posted anything other than a link to a blog post on X or any other social media for at least a year.
I enjoy my work on the R&D team at Awesome Motive where the last year has been spent deep in AI, working in Laravel, Google Cloud Platform, WordPress, and other tangential tools.
Much of the work we’re doing is building out tools and infrastructure that supports security initiatives, software for internal teams, and other utilities that are best described to fall under DevOps.
Projects
This year is the first time in a few years where I not only worked on a number of different side projects, but I worked on projects that use tech stacks with which I don’t frequently work. The advent of AI has made is much easier to go from nothing to something faster all the while learning something new at a faster rate.
Here’s a short list of what I published this year in chronological order:
Code Standard Selector for Visual Studio Code is a Visual Studio Code extension that makes it easy to switch your PHP coding standard without having to edit any settings in your IDE. And, yes, this will also work in any of the IDEs that are a fork of VS Code.
Remove Empty Shortcodes is a WordPress plugin I’ve revisited that automatically removes empty or inactive shortcodes from your WordPress content while preserving your original database entries.
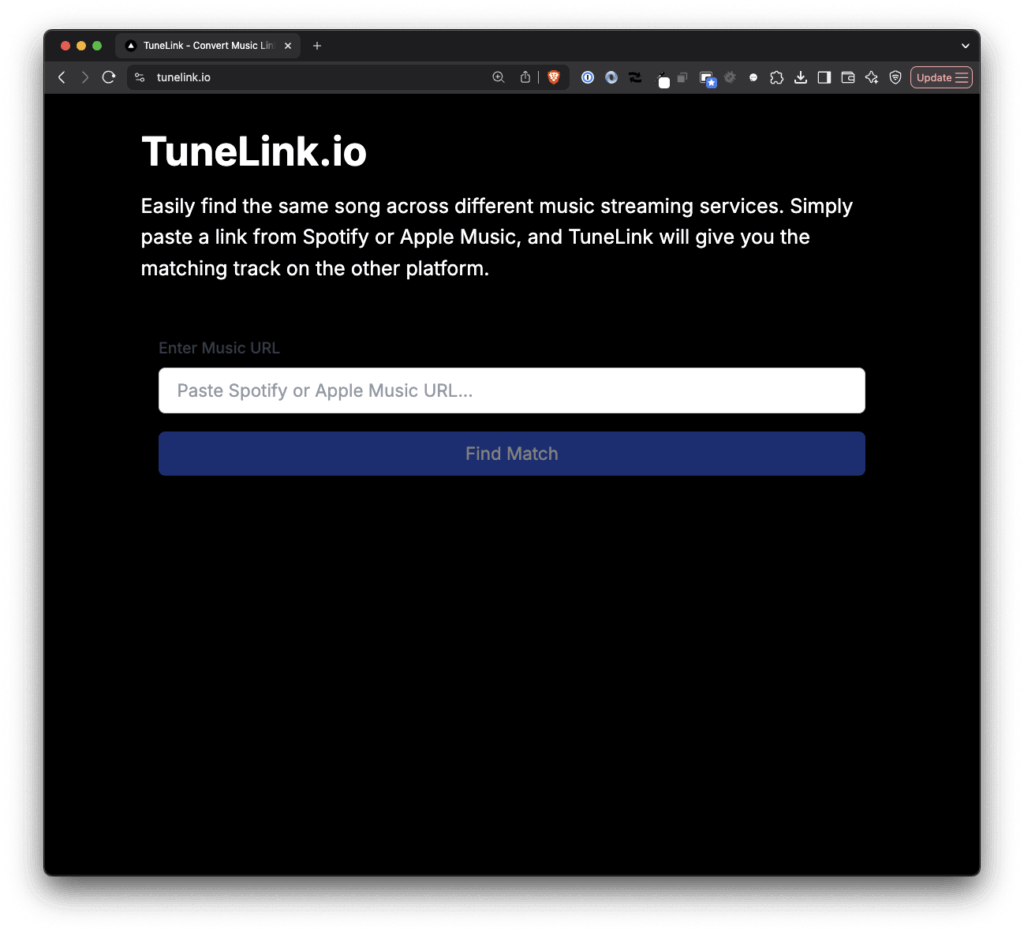
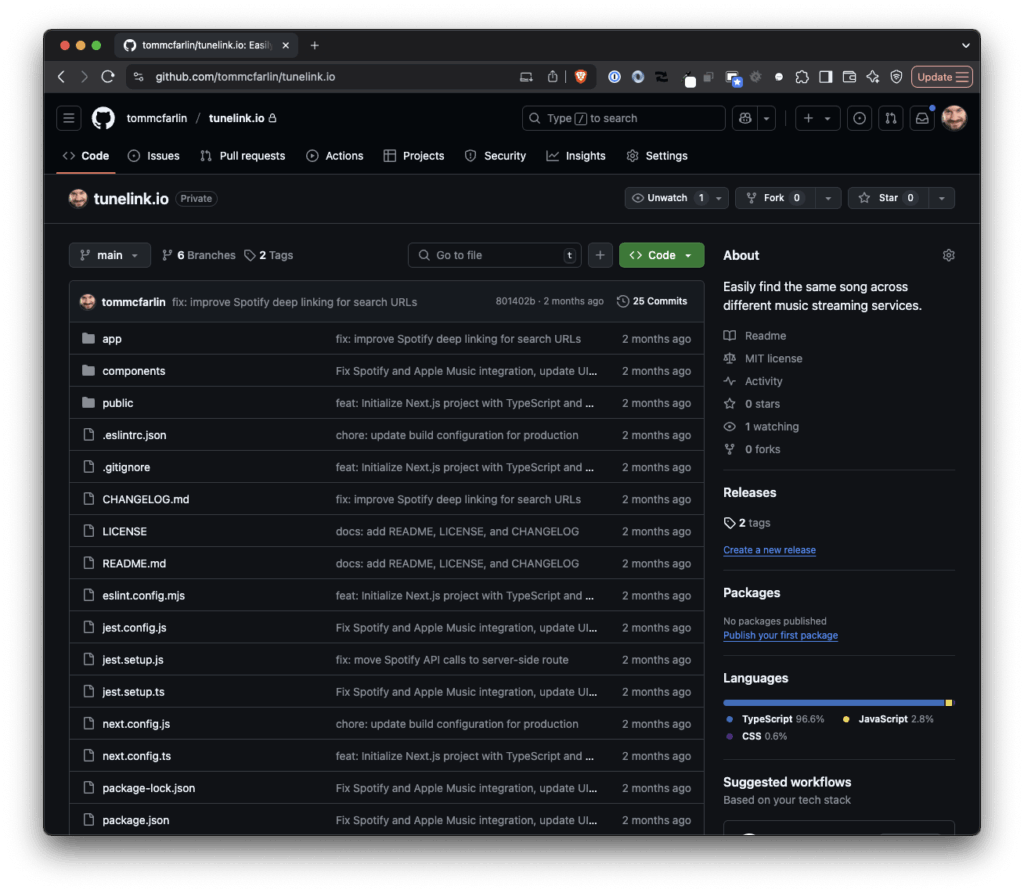
TuneLink.io For Matching Music Across Services allows you to easily find the same song across different music streaming services. Simply paste a link from Spotify or Apple Music, and TuneLink will give you the matching track on the other platform.
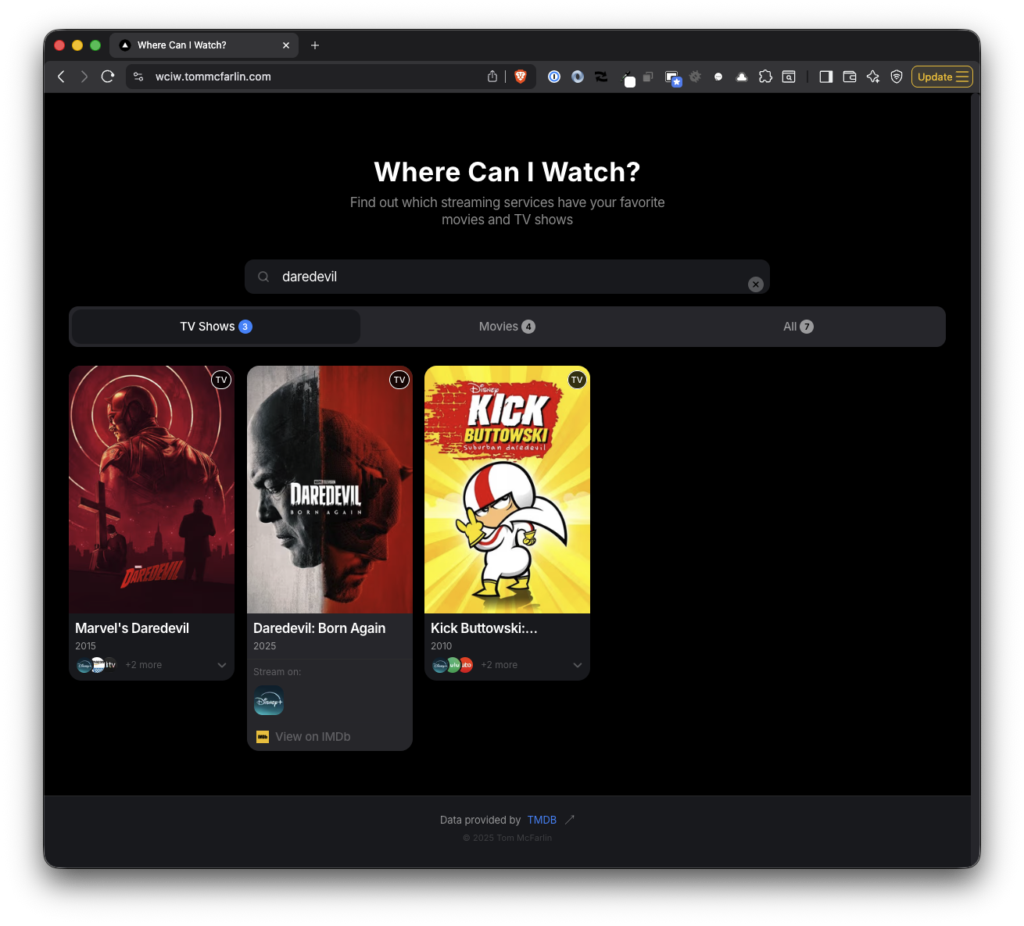
Where Can I Watch? is a web application that helps users quickly find which streaming services offer a particular show or movie.
Fetch Album Artwork for Apple Music Playlists is Python script to fetch album artwork for Apple Music playlists when given an artist and an album. This makes it a little bit easier to make sure album playlists have better looking artwork than what Apple Music generates on its own.
TM Monthly Backup is an aptly titled program I use for easily backing up photos, videos, screenshots, and even generated content from my Apple Photos library.
Last year, I shared the most popular posts that I’d published in 2024. This year, I thought it interesting to look at the most popular posts in terms of visits over the year as well as the most popular posts of 2025.
As years have passed, there’s an obvious shift in content an frequency but it’s neat to see the long tail some of these posts have (namely those that are still popular in 2025).
Books
I still try to read two books at a time – one fiction and one non-fiction – but I don’t but hard limits on how many books per month or whether or not they are the latest best sellers or most popular books. I aim to read what I want to read.
At the time of this writing, I read 22 books this year. I won’t list them all but some of the ones I enjoyed the most are:
Non-fiction
Farenheit-182by Mark Hoppus. Since I grew up listening to blink-182, this was a fantastic [and an easy] read. It hits a lot of high notes, glosses over some of the stuff that, although would’ve been interesting, wasn’t necessarily relevant to the core band.
The Comfort Crisisby Michael Easter. I decided to read this after hearing Michael on a podcast. The overarching lesson of the book is still worth reading, and I won’t spoil anything here, but I really like Easter’s writing style. He intersperses his personal story with the larger points he’s making.
On Writing by Stephen King. I’ve been reading his books for years so reading the only memoir he’s published and gaining insight into his process, along with some other fun anecdotes, made for a good read.
Future Boy by Michael J. Fox. Back to the Future is one of my top five favorite movies (in fact, I think it’s one of the only good time travel movies that exist) and Michael J. Fox is an incredible person so reading this was an easy choice. If you haven’t seen the documentary Still, it plays well in conjunction with the content of this book.
Fiction
The Dark Tower VII by Stephen King. I was in the fourth book at the end of last year and wrapped the series up in February of 2025. It made for a really great adventure. Yes, it has its weak points but overall it’s hard to find a modern epic that’s as sprawling as this series.
Sunrise on the Reaping by Suzanne Collins. I’ve enjoyed The Hunger Games since it was published and have also liked all of the additional stories Collins has written since. Given a choice between The Ballad of Songbirds and Snakes, which I also liked, I like this one even more.
Obviously, it wasn’t a big year for fiction. If there’s an honorable mention at least for the sake of discussion it would be The Cabin at the End of the World by Paul Tremblay. It was a book I picked up on a whim unaware that the movie Knock at the Cabin was based on it. It had a terrific hook from the first page but the ending did not hold up to the quality of the rest of the story.
Fitness
In September of last year, I pinched a nerve in my lower back which brought my usual routine to a halt. I was able to get back to walking by November and was back running on a treadmill and pushing weights by January.
Since then, I’ve had to make adjustments to my usual workouts. I don’t run outside anymore, unfortunately, but I still exercise five times a week and have primarily been doing a combination of running on the treadmill, strength training, and stretching every day. Once you pinch a nerve in your back, you’ll do just about anything to prevent it from happening again.
I’m still using Gentler Streak and have all the usual stats to share but the one that’s most important to me, given where I was last year, is this: Since logging all of my exercise via my Apple Watch since 2016, this is the first year since 2018 that I’ve exercised more cumulative time in an entire year. At the time of this writing, I’ve logged 162 hours and 5 minutes and 437.69 miles in 2025.
I don’t have a goal of trying to surpass this next year but if I can maintain this (I’m not getting any younger) and if I can avoid any further issues with my back, then I’ll be happy.
There’s a handful of other albums that I saved in Spotify this year (and, really, Subtitles for Feelings didn’t come out this year but I kept coming back to it). And for what it’s worth, there’s been a handful of synthwave and retrowave albums I listen to a lot when I work (most of them are by Timecop1983, FM-84, and The Midnight).
TV
As with last year, the majority of what I watch is whenever I’m on the treadmill or whenever Meghan and I are up for watching something before the day’s over. The shows I enjoyed most this year are (in no particular order):
Daredevil: Born Again. Though it felt a bit different from the Netflix series (reshoots and rewrites will do that), it found its footing before the end of the series and I’m glad.
Severance. If you’ve seen it, you get it; if you haven’t, you should.
Slow Horses. I don’t know what took me so long to watch this show but once I started, it’s all I watched when exercising. I covered the first four seasons during the summer and finished just in time for the fifth season to start in the fall.
Welcome to Derry. I liked the novel, IT, and the Muschietti’s Chapter One but I wasn’t as much a fan of Chapter Two. So I was tepid about this series. It ultimately delivered but the scope starts wide and takes it a while to find its footing and a solid pace. If you’re a fan of the book but not up for the show, the final two episodes are worth a watch.
I’d be making a mistake not to mention Stranger Things. We’ve been fans since day one and though the show isn’t wrapped at the time of this writing, we’re still here for it.
Podcasts
The podcasts I’ve listened to this year versus years past doesn’t vary wildly but a few dropped off and some new ones found their way to my rotatation:
Over the last few years, my oldest daughter has been interested in playing the guitar. A little over a year ago, she fell into it hard and has been both playing and songwriting since.
She and I started an ‘album swap’ for lack of a better term (what would you call this in 2025, anyway?) where she recommends an album to me, I recommend one to her, and we listen for a couple of weeks. Then we ask each other questions and have a discussion about it.
We also record it and I archive it for future listening. It’s something I really enjoy – and is meaningful – right now. Fast forward a decade or two and I’m sure it’s going to be that much more so.
To 2026
As with anyone else, this year was also full of other milestones for the kids, our family, trips, and so on. But everything above are the personal highlights all of which are largely outside of work.
As I wrote last year:
These are the highlights for 2024. Like most, I have things that I’m planning to do in 2025 though I’ll wait until this time next year to share how everything went.
And I repeat that but for 2026 instead.
In retrospect, it’s been an incredibly full year in nearly every facet. Such is life the older we – and our kids – get. I’m consistently surprised how much we fit into a year and even more so in just how fast it passes.
Nonetheless, each year brings with it a combination of pursuing the same goals and interests as well as moving into new areas, as well. In that regard, there will always be something new to share.
With that, I hope your year was just as full and mostly good and the next is even better. Here’s to 2026.
Last year, around this time, I also wrote Review and Highlights of 2024 and have a similar post for 2025 scheduled to publish in a few days.
I mention all of those if for no other reason than it’s increasingly interesting (for me, at least) to look back at each year as far as my general career is concerned.
But for today, the only thing I’m really sharing is to say Merry Christmas and Happy Holidays.
Merry Christmas 2024
As I tend to say, regardless of what holiday you’re celebrating, I hope both this day and this time of year are good to you and yours.
My family celebrated Christmas with my in-laws a few days ago, are celebrating at home today, and will be with other family before the break is over. We also have an upcoming wedding in the family and some friends visiting from Maryland.
It’s very busy albeit very full time of year and I’m grateful for that.
I’ve previously written about using Laravel Herd as my preferred PHP development environment. Outside of my day-to-day work, I’m also working with a couple of friends on a project that includes an iOS app that talks to a REST API via headless WordPress backend.
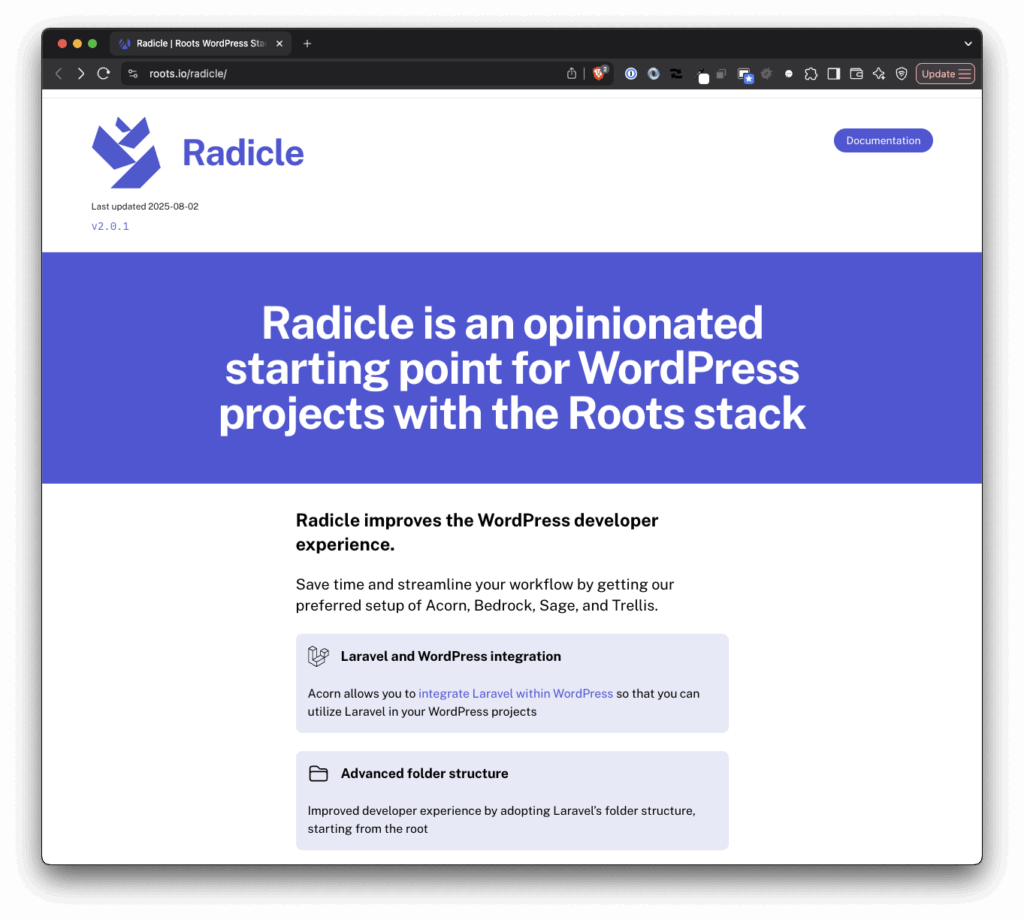
The web app is built using a set of tools from Roots including Radicle:
Radicle is an opinionated starting point for WordPress projects with the Roots stack.
In short, Radicle allows us to use features of Laravel within WordPress. But one of the challenges with my set up is getting Laravel Herd and Radicle to actually work.
Turns out, the solution isn’t that hard. And if you’re in a similar situation, here’s how to work with Radicle with Laravel Herd.
Roots Radicle with Laravel Herd
Project Set Up
First, I’m operating on the assumption that you have your project is already linked and secured with Herd.
In our case, we’re using a monorepo that contains both the iOS app and the web application. The web app in question is located in projects/monorepo-name/apps/wordpress. So I’ve issued the usual commands add that directly to Herd.
Secondly, I’ve got the .env file configured so that it has all of the necessary information for the database, various WP environmental variables, salts, and other information required to stand up the web app.
The Actual Problem
Third, and this was the most problematic, I had to add a custom driver that would allow Radicle to work with Laravel Herd. The path to custom drivers on your machine may vary but if you’re running the latest version of macOS and haven’t customized the Herd installation then it should look something like this:
Note that if the Drivers directory doesn’t exist, create it. Then touch a file named RadicleValetDriver.php in that directory and add the the following code (you shouldn’t need to change any of it):
<?php
namespace Valet\Drivers\Custom;
use Valet\Drivers\BasicValetDriver;
class RadicleValetDriver extends BasicValetDriver
{
/**
* Determine if the driver serves the request.
*/
public function serves(string $sitePath, string $siteName, string $uri): bool
{
return file_exists($sitePath.'/public/content/mu-plugins/bedrock-autoloader.php') &&
file_exists($sitePath.'/public/wp-config.php') &&
file_exists($sitePath.'/bedrock/application.php');
}
/**
* Determine if the incoming request is for a static file.
*
* @return string|false
*/
public function isStaticFile(string $sitePath, string $siteName, string $uri)/* : string|false */
{
$staticFilePath = $sitePath.'/public'.$uri;
if ($this->isActualFile($staticFilePath)) {
return $staticFilePath;
}
return false;
}
/**
* Get the fully resolved path to the application's front controller.
*/
public function frontControllerPath(string $sitePath, string $siteName, string $uri): string
{
$_SERVER['PHP_SELF'] = $uri;
if (strpos($uri, '/wp/') === 0) {
return is_dir($sitePath.'/public'.$uri)
? $sitePath.'/public'.$this->forceTrailingSlash($uri).'/index.php'
: $sitePath.'/public'.$uri;
}
return $sitePath.'/public/index.php';
}
/**
* Redirect to uri with trailing slash.
*
* @return string
*/
private function forceTrailingSlash(string $uri)
{
if (substr($uri, -1 * strlen('/wp/wp-admin')) == '/wp/wp-admin') {
header('Location: '.$uri.'/');
exit;
}
return $uri;
}
}
Note this is running on PHP 8.4 so you may need to adjust your function signatures and other features if you’re running on a significantly lower version (though I didn’t really test thing on anything lower than 8).
Once done, you should be able to load your project in the web browser. If not, restarting Herd’s services should do the trick. And, on the off change you still have an error, the stack trace should be easy enough to follow to see where the problem lies.
Given a vanilla Herd set up and Radicle integration with your WordPress project, this custom driver should be all you need to get everything working with as little effort as possible.
The two music streaming services I often swap between are Spotify and Apple Music. I prefer Spotify for a number of different reasons, the main reason being I like its music discovery algorithm more than any other service.
You have your own for your reasons.
But every now and then, there’s that case when someone sends me a song and, if I like it, I want to add it to Spotify. Or maybe I know they use Apple Music so I just want to send them a link directly to that song so they don’t have to try to find it on their own.
I know this isn’t an actual problem – it’s a minor inconvenience at best.
As the software development industry has moved so quickly with AI over the last few months (let alone the last few years), minor inconveniences become opportunities for building programs to alleviate their frustration.
And that’s what I did with TuneLink.io. In this article, you can read both what the web app does and how I built it with the help of AI and my opinion on using AI to build something outside of my wheelhouse.
TuneLink.io: Algorithms, APIs, Tech Stack, and AI
As the homepage describes:
TuneLink allows you to easily find the same song across different music streaming services. Simply paste a link from Spotify or Apple Music, and TuneLink will give you the matching track on the other platform.
A few things off the top:
It only works between Spotify and Apple Music (that is, it doesn’t include any other streaming services),
It’s not an iOS app so there’s no share sheet for easily sharing a URL to this site,
I do not pay for an Apple Developer License so the methods I used to find match music from Spotify and Apple Music are as precise as possible without an API access.
This is something I built to solve an inconvenience for me that I’m sharing here. And if it helps, great. There are also some learnings around the tech stack that I share later in the article, too. Further, I discuss how AI played a part in building it and I share a few thoughts on the benefits thereof.
So if you’re interested in how a backend engineer moves to using front-end services and serverless hosting, this article has you covered.
Recall, the primary inconvenience I wanted to resolve was being able to share an accurate link to a song to a friend who’s using a different music service than I do.
Similarly, I want to be able to copy a URL from a message that I receive on my phone or my desktop, paste it into the input field, and then have it generate an application link to automatically open it in my preferred music service.
It does exactly that and only that and you can give it try, if you’re interested.
All things considered (that is the desired architecture, how I wanted it to work, and experience with a number of LLMs), it took very little time to build I’ve not bothered sharing the site with anyone else (mainly because it’s for me). That said, there is a GitHub repository available in which you can file issues, feature requests, pull requests, and all of the usual.
But, as of late, I’ve enjoyed reading how others in this field build these types of things, so I’m doing the same. It’s lengthy so if you’re only interested in the utility itself, you have the URL; otherwise, read on.
How I Built TuneLink.io (Algorithms, APIs, and AI)
Earlier, I said the key to being able to build something like this – as simple as it is – is accelerated by having several key concepts and levels of experience in place.
This includes, but is not limited to:
Being able to clearly articulate the problem within a prompt,
Forcing the LLM to ask you questions to clarify understanding and knowing how to articulate a clear response to it,
Knowing exactly how the algorithm should work at a high-level,
Getting the necessary API keys from the services needed and making sure you’re properly incorporating them into local env files and setting up gitignore properly so not to leak information where needed,
Having a plan for how you want the app to function,
Preparing the necessary hosting infrastructure for hosting,
And knowing certain underlying concepts that can help an LLM get “un-stuck” whenever you see it stating “Ah, I see the problem,” when it definitely does not, in fact, see the problem (as the kids say, iykyk).
Okay, with that laid as the foundation for how I approached this, here’s the breakdown of the algorithm, dependencies, APIs, and the tech stack used to build and deploy this.
And remember: All TuneLink is is a single-page web app that converts URLs from one music service to another and opens the track in the opposite music service.
The Algorithm
URL Analysis and Detection
The first step in the process is determining what information is available with which to work. When a user pastes a URL into TuneLink, the application needs to:
The algorithm uses regular expressions to match these patterns and extract the critical identifiers. If the URL doesn’t match any known pattern, it returns an error asking for a valid music URL.
Extracting Track Information
Once the program has identified the platform and extracted the IDs, it needs to gather metadata about the track:
For Spotify URLs: Query the Spotify Web API using the track_id
For Apple Music URLs: Query the Apple Music/iTunes API using the track_id
Extract the essential information: track name, artist name, album name
Since I’m not using an Apple Developer License, the iTunes API was easier to access as it doesn’t require any privileged data to access it.
This metadata becomes my search criteria for finding the equivalent track on the other platform. The more information I can extract, the better my chances of finding an accurate match. More specifically, there’s an interstitial API I used in conjunction with this information that I’ll discuss more in this article.
Cross-Platform Track Matching
Up to this point, the approach is easy enough. But this where it gets a more interesting. With the source track information now available, the program needs to find the same track on the target platform:
For Apple Music to Spotify conversion:
Extract track name and artist from Apple Music
Format a search query for the Spotify API: “{track_name} artist:{artist_name}”
Send the search request to Spotify’s API
Analyze the results to find the best match
Create the Spotify URL from the matched track’s ID
For Spotify to Apple Music conversion:
Extract track name and artist from Spotify
Format a search query for the iTunes Search API: “{track_name} {artist_name}”
Send the search request to iTunes API
Filter results to only include songs from Apple Music
Create the Apple Music URL from the matched track’s information
The matching algorithm uses several criteria to find the best result:
Exact matches on track name and artist (which obviously yields the highest confidence)
Fuzzy matching when exact matches aren’t found
Fallback matching using just the track name if artist matching fails
Duration comparison to ensure we’ve got the right version of a song
Following a fallback hierarchy like this proved to be useful especially when there are various versions of a song in either service. This may include something that was live, remastered during a certain year, performed live at Apple, performed live at Spotify, etc.
Ultimately, the goal is to get the closest possible track to the one available if the identical track cannot be found. And I talk about this a little more in-depth later in the article.
Result Caching and Optimization
To improve performance and reduce API calls, there’s also a system that does the following:
Caches successful matches for frequently requested tracks
Uses a tiered approach to searching (exact match first, then increasingly fuzzy searches)
Handles common variations like remixes, live versions, and remastered tracks
This makes subsequent requests for the same track conversion nearly instantaneous.
The purpose here is not so much anticipating a lot of traffic but to simply gain experience in implementing a feature in a set of tools with which I’m less familiar.
In other words, this type of functionality is something commonly deployed in other systems I’m working on but I’ve not been exposed to it in the tech stack I’ve used to build TuneLink. This is a way to see how it’s done.
Error Handling and Fallbacks
This is another area where things became more challenging: Not all tracks exist on both platforms, so the algorithm needs to handle these cases gracefully.
As such, this is how the algorithm works:
If no match is found, try searching with just the track name.
If still no match, try searching with normalized track and artist names (removing special characters).
If no match can be found, return a clear error message.
Provide alternative track suggestions when possible.
Examples in which I saw this the most was when dealing with live tracks, remastered tracks, or platform-specific tracks (like Spotify Sessions).
The Full Algorithm
If you’re looking at this at a high-level or in a way in which you’d want to explain the algorithm using all of the details albeit at a high-level, it goes like this:
Take the input URL from user
Validate and parse URL to identify source platform
Extract track ID and query source platform’s API for metadata
Use metadata to search the target platform’s API
Apply matching logic to find the best corresponding track
Generate the target platform URL from the match results
Return the matching URL to the user
After trying this out over several iterations, it become obvious that using only the Spotify and iTunes APIs was going to be insufficient. I needed a way to make sure the fallback mechanism would work consistently.
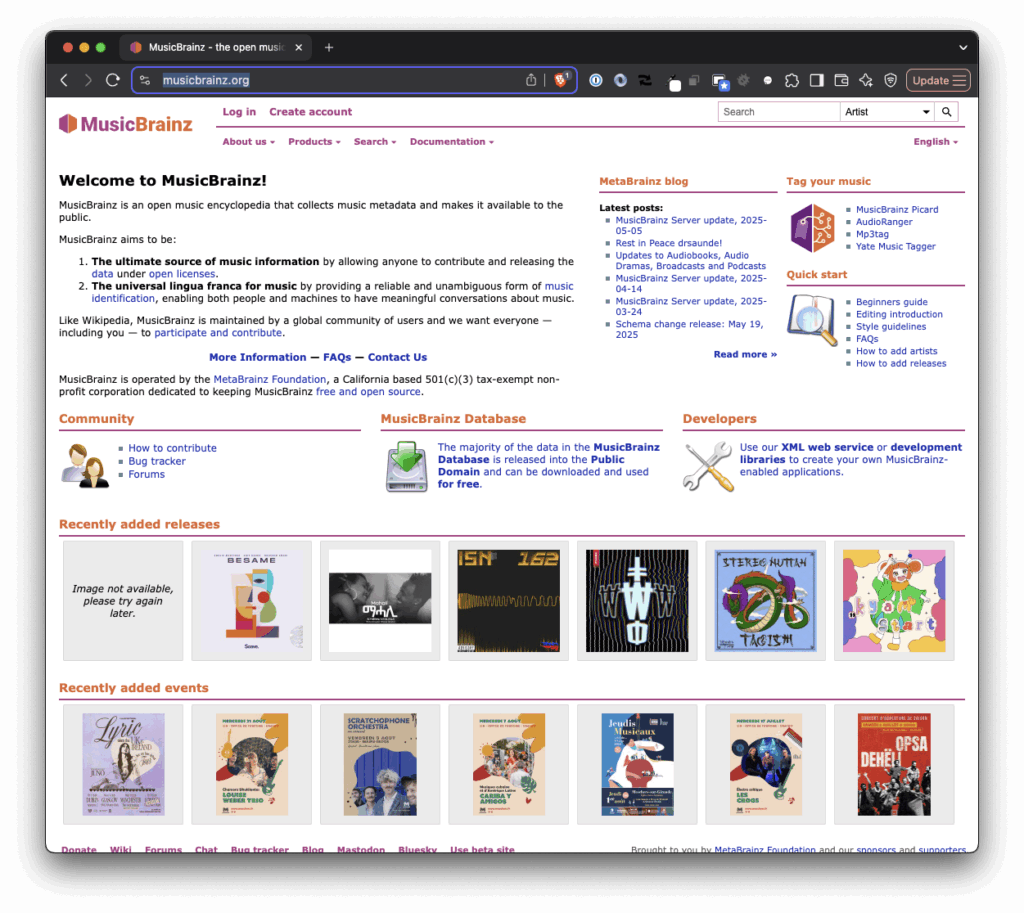
And that’s where a third-party API, MusicBrainz, helps to do the heavy lifting.
Matching Tracks with MusicBrainz
MusicBrainz is “an open music encyclopedia” that collects music metadata and makes it available to the public. In other words, it’s a Wikipedia for music information.
What makes it particularly valuable for TuneLink is:
It maintains unique identifiers (MBIDs) for tracks, albums, and artists
It provides rich metadata including alternate titles and release information
It’s platform-agnostic, so it doesn’t favor either Spotify or Apple Music (or other platforms, for that matter).
It has excellent coverage of both mainstream and independent music
It’s been really cool to see how the industry uses various pieces of metadata to identify songs and how we can leverage that when writing programs like this.
Integrating MusicBrainz in TuneLink
As far as the site’s architecture is concerned, think of MusicBrainz as an intermediary layer between Spotify and Apple Music. When using MusicBrainz, the program works like this:
Extract track information from source platform (Spotify or Apple Music)
Query MusicBrainz API with this information to find the canonical track entry
Once we have the MusicBrainz ID, we can use it to search more accurately on the target platform
Using this service is what significantly improved matching between the two services because it provides more information than just the track name and the artist.
Edge Cases
MusicBrainz is particularly valuable for addressing challenging matching scenarios:
Multiple versions of the same song. MusicBrainz helps distinguish between album versions, radio edits, extended mixes, etc.
Compilation appearances. When a track appears on multiple albums, MusicBrainz helps identify the canonical version
Artist name variations. MusicBrainz maintains relationships between different artist names (e.g., solo work vs. band appearances)
International releases. MusicBrainz tracks regional variations of the same content
Even still, when there isn’t a one-to-one match, it’s almost always a sure bet to fallback to the studio recorded version of a track.
Fallbacks
To handle the case of when there isn’t a one-to-one match, this is the approach taken when looking to match tracks:
First attempt. Direct MusicBrainz lookup using ISRCs (International Standard Recording Codes) when available
Second attempt. MusicBrainz search using track and artist name
Fallback. Direct API search on target platform if MusicBrainz doesn’t yield results
Clearly, I talked about Error Handling and Fallbacks earlier in the article. Incorporating this additional layer made results that more robust.
API Optimization
To keep TuneLink responsive, I implemented several optimizations for MusicBrainz API usage:
Caching. I cache MusicBrainz responses to reduce redundant API calls.
Rate Limiting. I carefully manage the query rate to respect MusicBrainz’s usage policies.
Batch Processing. Where possible, I group queries to minimize API calls.
Using MusicBrainz as the matching engine creates a more robust and accurate system than would be possible with direct platform-to-platform searches alone.
This approach has been key to delivering reliable results, especially for more obscure tracks or those with complex release histories.
The Tech Stack
The primary goal of the TuneLink site was to have a single page, responsive web application that I could quickly load on my phone or my desktop and that made deployments trivially easy (and free, if possible).
Frontend Technology
TuneLink is built on a modern JavaScript stack:
Next.js 15. The React framework that provides server-side rendering, API routes, and optimized builds
React 19. For building the user interface components
TypeScript. For type safety and improved developer experience
Tailwind CSS. For styling the application using utility classes
Zod. For runtime validation of data schemas and type safety
This combination gave the performance benefits of server-side rendering while maintaining the dynamic user experience of a single-page application.
Backend Services
The backend of TuneLink leverages several APIs and services:
Next.js API Routes. Serverless functions that handle the conversion requests
MusicBrainz API. The primary engine for canonical music metadata and track matching
Spotify Web API. For accessing Spotify’s track database and metadata
iTunes/Apple Music API. For searching and retrieving Apple Music track information
Music Matcher Service. A custom service I built to orchestrate the matching logic between platforms. Specifically, this is the service that communicates back and forth from the music streaming services and MusicBrainz.
Testing and QA
To ensure reliability, TuneLink includes:
Jest. For unit and integration testing
Testing Library. For component testing
Mock Service Worker. For simulating API responses during testing
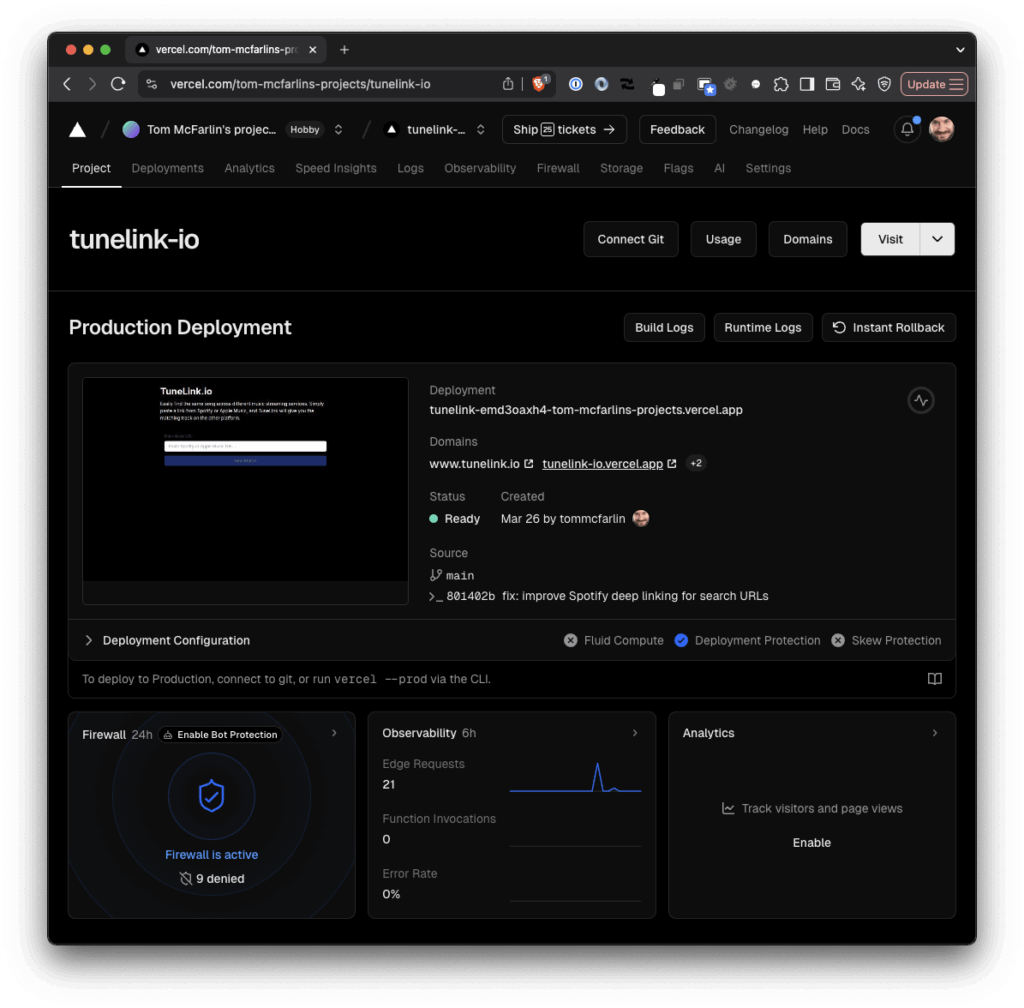
Hosting and Infrastructure
TuneLink is hosted on a fully serverless stack:
Vercel. For hosting the Next.js application and API routes
Edge Caching. To improve response times for frequently requested conversions
Serverless Functions. For handling the conversion logic without maintaining servers
This serverless approach means TuneLink can scale automatically based on demand without requiring manual infrastructure management. Of course, an application of this size has little-to-no demand – this was more of a move to becoming more familiar with Vercel, deployments, and their services.
And for those of you who have historically read this blog because of the content on WordPress, but are are interested in or appreciate the convenience of Vercel, I highly recommend you take a look at Ymir by Carl Alexander. It’s serverless hosting but tailored to WordPress.
Development Environment
For local development, I use:
ESLint/TypeScript. For code quality and type checking
npm. For package management
Next.js Development Server. With hot module reloading for quick iteration
Why This Stack Over Others?
I chose this technology stack for several reasons:
Performance. Next.js provides excellent performance out of the box
Developer Experience. TypeScript and modern tooling improve code quality
Scalability. The serverless architecture handles traffic spikes efficiently
Maintainability. Strong typing and testing make the codebase more maintainable
Cost-Effectiveness. Serverless hosting means we only pay for what we use
This combination of technologies allows TuneLink to deliver a fast, reliable service while keeping the codebase clean and maintainable. The serverless architecture also means zero infrastructure management, letting me focus on improving the core matching algorithm instead of worrying about servers.
Conclusion
The whole vibe coding movement is something to – what would you say? – behold, if nothing else, and there’s plenty of discussions happening around how all of this technology is going to affect the job economy across the board.
This is not the post nor am I the person to talk about that.
In no particular no order, these are the things that I’ve found to be most useful when working with AI and building programs (between work and side projects, there are other things I can – and may – discuss in future articles):
I know each developer seems to have their favorite LLM but Sonnet 3.7 has been and continues to be my preferred weapon of choice. It’s worked well across standard backend tools with PHP, has done well assisting in programs with Python, and obviously with what you see above.
The more explicit and almost demanding of what you can be with the LLM, the better. Don’t let it assume or attempt to anything without explicit approval and sign off.
Having a deeper understanding of computer science, software development, and engineering concepts in helpful primarily because it helps to avoid common problems that you may encounter when building for the web.
Thinking through algorithms, data structures, rate limits, scaling, and so on is helpful when prompting the LLM to generate certain features.
There are times when an attempt at a one-shot for a solution is fine, there are times when an attempt to one-shot a feature is better. I find that intuition helps drive this depending on the context in which you’re working, the program you’re trying to write, and the level of experience you have with the stack with which you’re working.
Remembering to generate tests for the features you’re working on and/or are refining should not be after thoughts. In my experience, even if an LLM generates subpar code, it does a good job writing tests that match your requirements which can, in turn, help to refine the quality of the feature in quest.
Regardless of if I’m working with a set of technologies with which I’m familiar or working with something on which I’m cutting my teeth, making sure that I’m integrating tests against the new features has been incredibly helpful in more than one occasion for ensuring the feature does what it’s supposed to do (and it helps to catch edge cases and “what about if the user does this?“). As convenient as LLMs are getting, they aren’t going to be acting like rogue humans. I’m think there’s a case to be made they often don’t act like highly skilled humans, either. But they’re extremely helpful.
This isn’t a comprehensive list and I think the development community, as a whole, is a doing a good job of sharing all of their learnings, their opinions, their hot takes, and all of that jazz.
I’ve no interest in making any type of statement that can be any type of take nor offering any quip that would fall under “thought leadership.” At this point, I’m primarily interested and concerned with how AIs can assist us and how we can interface with them in a way that forces them to work with us so we, in turn, are more efficient.
Ultimately, my goal is to share how I’ve used AI in an attempt to build something that I wanted and give a case study for exactly how it went. I could write much more about the overall approach and experience but there are other projects I’ve worked on and I am working on that lend themselves to this. Depending on how this is received, maybe I’ll write more.
If you’ve made it this far, I hope it’s been helpful and it’s help to cut through a lot of the commentary on AI and given a practical look and how it was used in a project. If I ever revisit TuneLink in a substantial way, I’ll be sure to publish more about it.
Kinsta offers premium managed WordPress hosting for everyone, small or large. Powered by Google Platform and strengthened by Cloudflare, they take performance to the next level. All hosting plans include 24/7/365 support from their team of WordPress engineers. Get startedwith a free migration today.