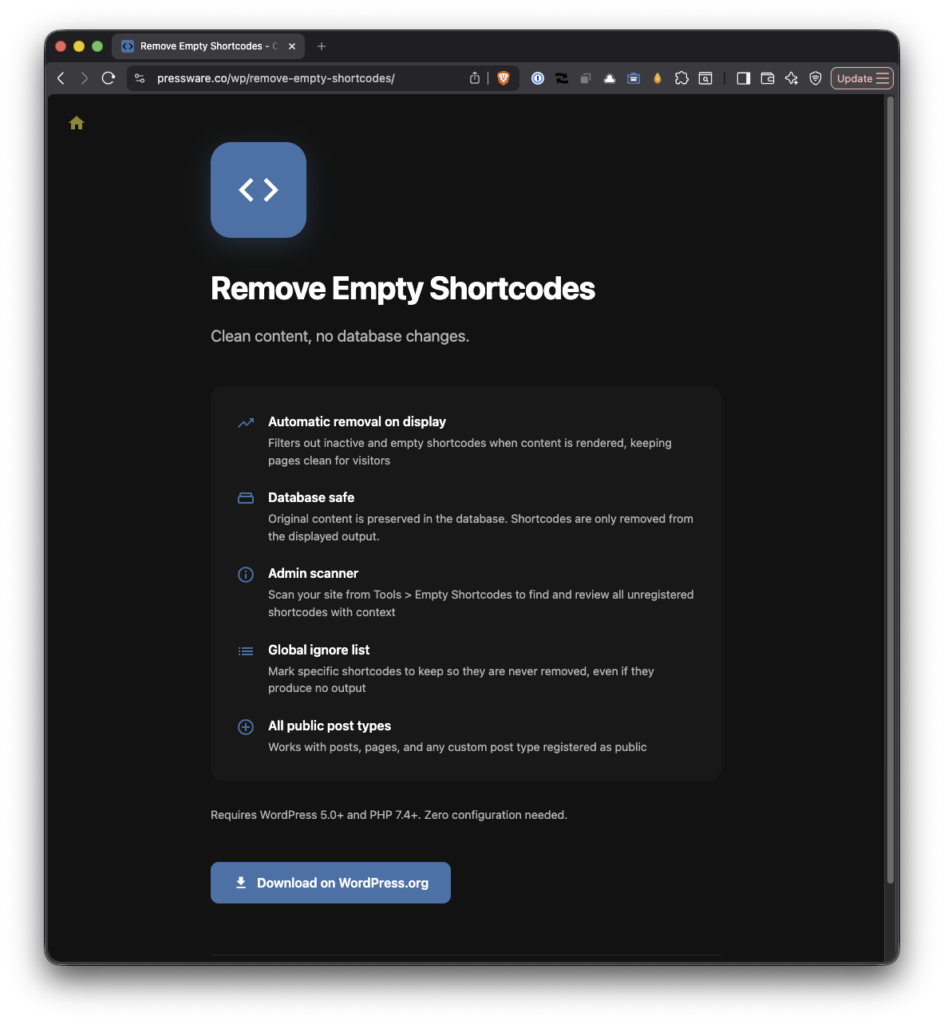
A couple of weeks ago, I shared Remove Empty Shortcodes 1.1.0, which improved the plugin to do the one thing it exists for again: strip out the inactive shortcodes a deactivated plugin or page builder leaves behind. It worked. It just didn’t work everywhere.
1.2.0 is where “everywhere” finally means everywhere.
Continue reading