Yesterday, I gave a primer on the repository pattern. In short, it’s one of those patterns that I think anyone working on middleware built on top of WordPress should understand.
When giving a primer on a pattern like this, it can be tough to do justice to the pattern when you need to:
- introduce it,
- explain how it works,
- cover the benefits,
- and give a small demo.
But the real advantage to the repository lies not only in abstracting the data layer away from the rest of the application but that it can (or should) be able to be easily swapped out with various data stores without changing the API.
For example, in one instance, you may need to retrieve data from the WordPress database, in other cases you may need to retrieve something from a third-party API, or perhaps there’s some other place from which you need to retrieve data.
Regardless, the idea behind the repository pattern is that whatever sits behind it doesn’t matter so long as the API it provides works for the layer of the application calling into it.
And since we’ve covered a primer on the repository pattern, let’s take a look at some of the repository pattern benefits and how we can implement it in the context of WordPress projects.
Repository Pattern Benefits
There are some ways to begin explaining the pattern, so I’m going to start with a simple diagram:
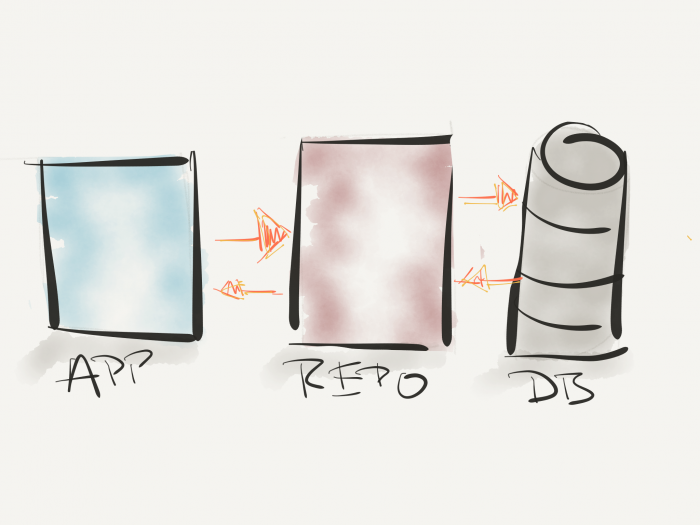
Repository Pattern Benefits include Data Store Abstraction
Notice in the image above, there are three main components:
- the domain logic (or the business logic) which I’ve labeled “App”,
- the repository,
- the data store,
Regarding the application, the business rules will always remain relatively consistent. At least they should, right?
The repository is what acts as a means of communication between the business logic and the data store.
Now the data store can be a database, perhaps a set of files (which I wouldn’t recommend), an API to a third party, a list of information retrieved from another application, and so on.
The point is that the repository will provide a clean API that the business logic can write to and read from (and more on this in a moment) without worry about the details of where the data is going or how it’s coming back.
That’s the job of the repository. And that’s what makes it important to have a consistent API and that’s what’s important to make sure it has the implementation details of the data store with which it’s interacting.
On Coupling
Aside from having your application properly segmented, the repository pattern benefits the architecture in that it helps decouple the parts of your application.
That is, the business logic knows nothing about how or where the data is stored. It just knows it can write it and retrieve it and it can do so using a clean API.
The repository is responsible for communicating said data store to orchestrate serialization and retrieval but must provide a consistent API, so the data layer doesn’t have to do any syntax gymnastics to read and write its information.
Implementation Details
Up until this point, I’ve been representing the repository as a concrete class.
The thing is, an application will likely have multiple repositories. And because of that, it’s a good idea to have interfaces that each repository can implement.
This is how you define the contract of methods the repository will provide. And this is how you can ensure each repository is connected to the proper data store.
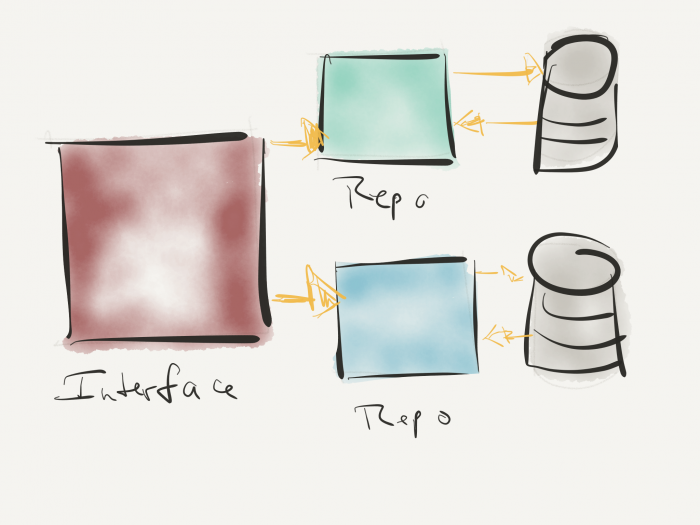
An interface implementation for multiple repositories.
So let’s say your application needs to talk to the WordPress database as well as a third-party API.
Ideally, the interface would provide a common set of methods, but the implementation details would vary on a per-repository basis because each repository will have the necessary credentials and ability to communicate with the data store.
The advance to the interface though is what gives the pattern its power. The domain logic doesn’t have to worry about how the information is saved or how it’s retrieved. It simply calls the methods as defined in the interface and the necessary object takes care it.
It simply calls the methods as defined in the interface and the necessary object takes care it.
What Would This Look Like in WordPress?
This is a good question (and no I didn’t make it up just to answer it on my own 🙂), and it can be difficult to give a great example because so much of what we do interacts directly with the WordPress database.
This doesn’t mean there aren’t abstractions we can use such as Posts, Pages, Users, or whatever other custom post types we opt to create.
But WordPress does provide an API for much of this. I can see a case in which, say, a user with additional fields that have been added could benefit from a User Repository.
Or a custom post type with a lot of metadata could also benefit from a repository by having the details encapsulated into the repository.
A High-Level Example
Say, for example, you have a custom post type for an Event, and the event has a title and description which would naturally fit within the post title and post content.
But then it has metadata about its location, its start time, its end time, and so on. That could also be encapsulated by the repository so you could have an Event object, pass it to the repository, and then let the repository send the information to the proper place in the database.
And the same goes for retrieving the information: It knows where to get it, how to populate an Event object, and then hand it back to the caller.
Back On Track
But all this talk about an Event is getting a bit off topic, so perhaps I’ll continue talking about that and how it fits in with the repository in a follow-up post. Clearly, when talking about this, there’s a lot to cover.
I’d rather take it in smaller steps
In short, if you have an Event Repository you likely have an Event object or an Event entity. And how this fits into WordPress, custom post types, metadata, and so on introduces a level of complexity that may seem daunting at first but ultimately pays off when working with a larger web application.
Leave a Reply
You must be logged in to post a comment.