Whenever you’re working on a larger project that’s based on WordPress, the odds that you’re going to be working with more than a single data source – that is, the WordPress database – are higher than normal. For example, you may be working on a project that has to coordinate information from:
- the WordPress database,
- a help desk ticketing system,
- a content importing system,
- another third-party API,
- and possible more.
And when this happens, it can become a bit cumbersome to write code that makes it easy to retrieve information from those different places. This what developers usually talk about when they refer to dealing with “layers” in their application. That is,
- there are layers for presenting information to the user,
layers for handling business logic (or domain logic), - layers for communicating with APIs,
- and layers for storing data.
Honestly, you don’t have to have a variety of data stores to watch to create a layer that makes it easier to send and retrieve data from the database, that’s just when it’s more common. You can just as effectively work with a single data store, like the WordPress database, when implementing the repository pattern.
Regardless, if you’re building a larger website, web application, or plugin, implementing the repository pattern is something that can pay dividends in maintenance, clarity of code, and separation of concerns.
But how might this be implemented within WordPress? It’s not terribly challenging, but first, it’s worth reviewing a repository primer before jumping into any code.
A Repository Pattern Primer
Before looking at an actual implementation in WordPress, it’s important to understand what the repository is, how it’s defined, what it offers, and a generic implementation of it. I’ll share some further reading at the end of the article, but until then I’ll cover my general take on the pattern here.
First, an implementation of this pattern can become more complicated than necessary for beginners. This isn’t to say that the actual pattern isn’t worth understanding, but if you’re just looking to get your wet with this, I’m not a fan of throwing readers into the deep end. I don’t think it’s the best way to learn.
Instead, it’s worth breaking down the problem then rebuilding it into something a little more elegant. So that’s what I’m going to aim to do.
A Word About Decoupling
When talking about object-oriented programming, we often talk about the idea of “decoupling” parts of the system. If you’re familiar with coupling and cohesion, then you know why.
But if not, suffice it to say that the more coupled the components your system are, the harder they are to change. They know too much about one another. That is, if you change one of the aspects of the system, it’s likely going to cascade or impact another part of the system that you never meant to happen. Then you’re left when having to spend far more time fixing all of these other “touch points” throughout the system that shouldn’t be necessary.
Implementing various strategies, like the repository pattern, can help decouple parts of the system. Case in point: The presentation layer doesn’t know to know how the underlying datastore is organization. It doesn’t need to know SQL. It doesn’t need to know it’s a database. Instead, it just needs to know how to talk to the repository.
Nice, right?
This means you can swap out the backend data store and, assuming your API is solid; your application will continue to function with little-to-no change. And that’s what it means to be truly decoupled.
An Implementation of The Repository Pattern
So what does the repository pattern look like? As with most design patterns, there is a generic form of the pattern, and that’s always helpful, but I think it also helps those of us working in WordPress to see how it might work within the context of, y’know, WordPress.
So first, I want to break down the pattern itself and then give an example of what it might look like when working with WordPress.
A Generic Implement of The Repository Pattern
The actual implementation of the repository pattern is pretty simple. In fact, I’m not ever sure if it’s that helpful because it just shows how the data stores, the repository, and the rest of the application interact with each other.
Don’t get me wrong: I’m all for conceptual models of how things are organized. Personally, it helps me think about the structure of an application when building it, but if it’s too general, it’s not much help.
But to get to a concrete implement, we have to start somewhere, right? So I’ll start at the highest level possible and work down.
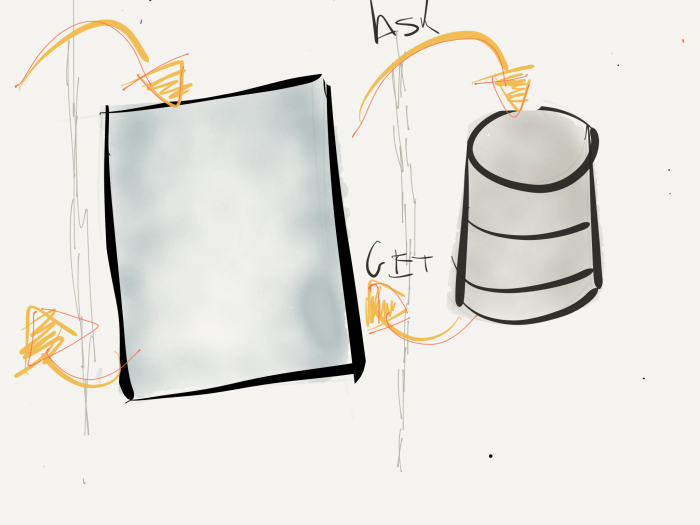 As you can see in the image above, you’ve got a couple of data stores all of which are read via the repository, and then the application queries the repository which, in turn, retrieves information from the data store.
As you can see in the image above, you’ve got a couple of data stores all of which are read via the repository, and then the application queries the repository which, in turn, retrieves information from the data store.
Yes, there are options to cache information, invalidate the cache, and all that fun stuff. But it’s outside the scope of a primary of the repository. So I’m not going to go down that particular path for now. Perhaps in a future post (should this one prove useful to you).
The Repository Pattern in WordPress
So with that said, let’s take a look at a basic implementation of what this might look like in a standard WordPress installation. That is, all we have is the data store. We aren’t communicating with anything else, but we want to make sure anything that interfaces with the database or the API is handled by the repository
This would look something like this:
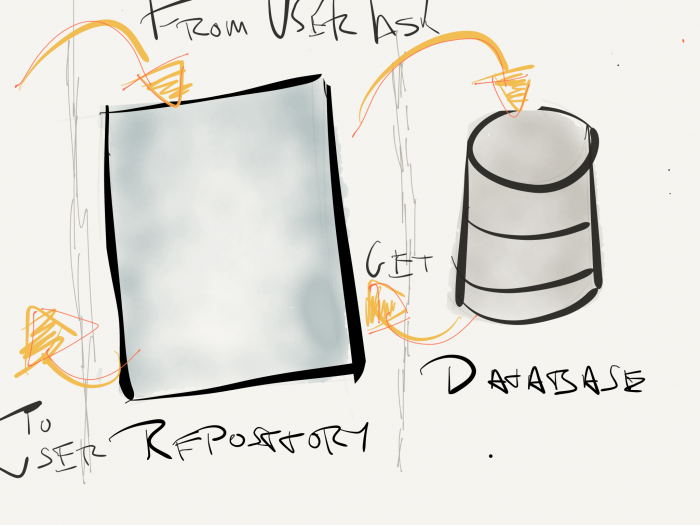
How it might look with WordPress
And this can be abstracted even further. Perhaps there’s a Post Repository or a User Repository. Personally, I’m a fan of having a repository for each type of entity because it helps to contain related business logic without creating those big classes that know everything (and unnecessarily so).
So this might look like this:
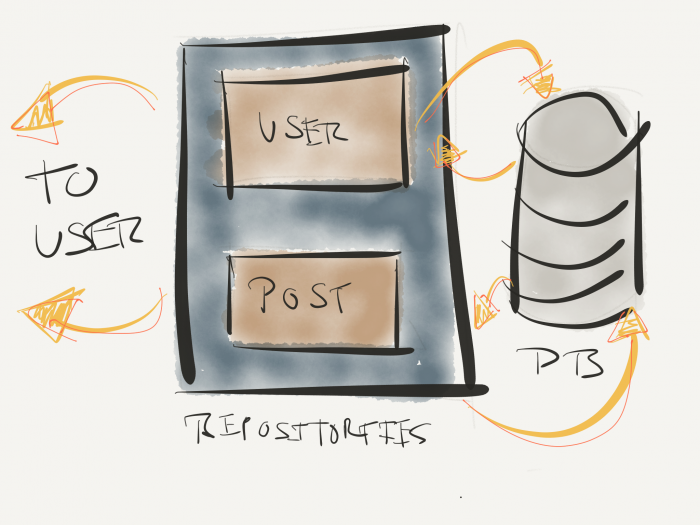
A Package of Repositories
Then let’s take it up one more level and say you’re working with the Twitter API, the ZenDesk API, the WordPress User API, and the WordPress Post API. Then what? There are more repositories.
Perhaps they are contained in their namespace (which they should be), maybe they are implementing a common interface (for which there is a case for this), but during development time, I think it’s important to explicitly state which repository you’re using so to be as clear as possible.
That is, don’t use a generic and let runtime figure it out:
$support_repository = new Support_Repository(); $support_repository->get_tickets_for( 'tommcfarlin' );
Instead, be explicit:
$zendesk_repository = new ZenDesk_Repository(); $zendesk_repository->get_tickets_from( 'yesterday' );
This might feel like a lot. I don’t know if you experience this, but there’s a weird feeling in object-oriented programming where we want to create the small, focused classes but it creates a lot of files.
So you have these neatly set up files each of which is doing something small and purposeful. Don’t let the number of files that compose a project give the impression you have a poor architecture.
Conclusion
This is the primer on the repository pattern. Naturally, there’s code that goes along with this, but before diving into that part – because code is where things that get lost in translation easily – I wanted to make sure I helped provide an illustration to develop a conceptual model for how the pattern works.
From here, we can begin talking about an implementation of the pattern. So over the next post or next couple of posts, I’m going to do exactly that.
In the meantime, don’t hesitate to leave any comments or questions about what’ve covered here.
Leave a Reply
You must be logged in to post a comment.