Assuming that you’ve been following along with the majority of the posts in this series, then you know that we’ve been looking at ways to handle input sanitization and serialization in the WordPress Settings API from an object-oriented perspective.
As of now, we’ve got all of the necessary pieces for doing so, but we’ve not actually tied them all together. So in this post, I’m going to aim to do that in one of the many different ways this can be done.
I’ll talk about how to do it using the code we’ve written as well as some more advanced improvements that can be made were you to take this a few steps further.
The WordPress Settings API and Architecture
When it comes to building plugins (or any software for that matter), the way in which you opt to architect your code is going to vary from what others may do.
That’s okay.
There are different ways to go about achieving the same results. Sure, some ways are going to be better than others, and I’m not saying that just because something works means that it’s sufficient, but for the purposes of this post, if you find yourself wanting to do it a different way or thinking that what I’ve provided isn’t sufficient, then please feel free to share your approach in the comments.
I’m always willing to refactor, improve, or answer any questions around the rationale of what I have so far.
With that said, you can review all of the code by looking back at the series thus far or you can take a look at the complete gist (Gist 1 and Gist 2) of the code that’s gone into the series.
How Do All of The Parts Relate?
Remember that, when it comes to the WordPress Settings API, we have a lot of different parts all working in tandem:
- We’re displaying the input fields with which the user interacts
- We’re examining the information and sanitizing it (or rejecting it)
- We’re displaying error messages
- We’re saving and/or retrieving the data from the database
And all of the these parts ultimately allow the user to achieve the following:
- Save their input into the database
- Retrieve their previous input
- Edit the input
- Repeat
Obviously, there’s a lot that happens in between – I mean, we just covered how we have to examine the input before it hits the database and we have to do this each time.
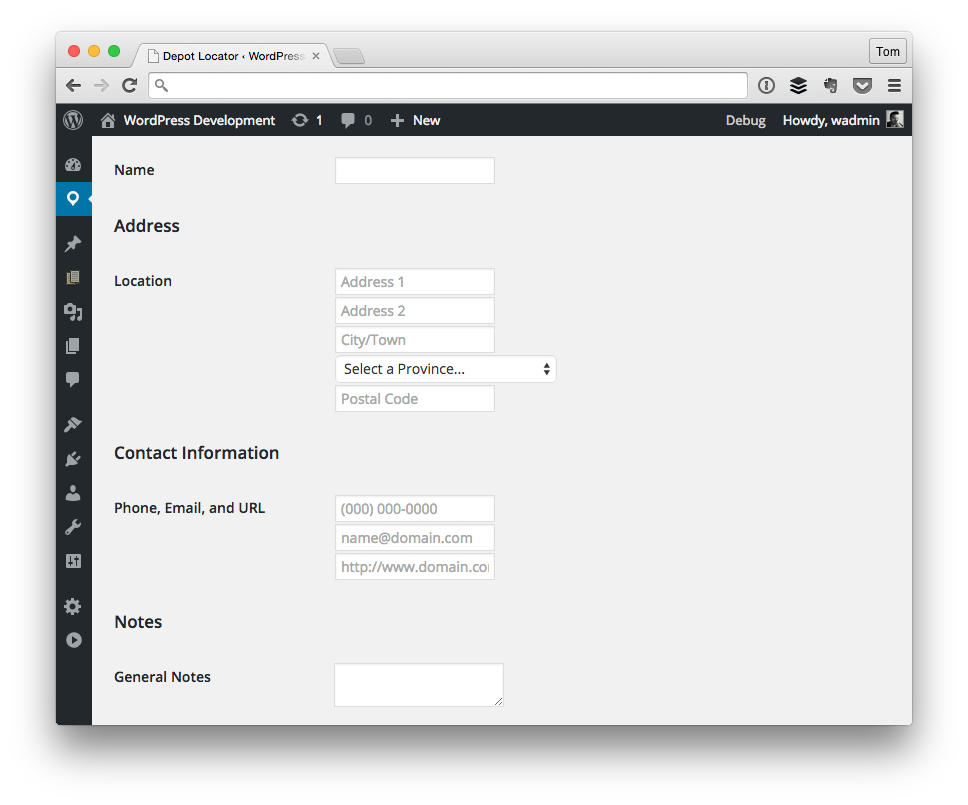
An Example Settings Page
Anyway, the reason I mention this is so that we all have somewhat of a common conceptual model of what’s going on with respect to the code that we’re about to see. Note that the following code samples assume that you’re familiar with the WordPress Plugin API and that you’re familiar with how to get started with bootstrapping a plugin.
We aren’t going to be covering any of that here so, if not, the Codex is a pretty good resource and I’ve covered this quite a bit on this blog throughout the past several years.
The point of what we’re going to see, though, is how we associate all of the classes together so that when the user opts to sanitize the information, it’s passed to the proper class and then sanitized or it’s rejected and an error message is displayed.
So with that said, let’s take a look at the absolute basic code necessary to get our previous code up and running so that we can see how to implement this within the context of a complete (or larger) plugin.
Validating Our Fields
Remember that we’re validating three fields:
- The address
- The city
- The postal code
So we’ll look at how these classes may look when coupled with the validation classes created in the previous post.
The Address
Recall from the initial sanitization method of the address that we were originally doing this in order to sanitize the data:
And that’s straight forward enough, right?
At this point, though, we’ve introduced a class based on an interface that’s designed specifically for this setting. This allows us to separate the logic based on its responsibility, to continue working on it so that it may be more strict or less strict depending on your validation rules, and allows us to define our own custom error messages.
Recall that the address’ sanitization code looks like this:
To tie this all together, we need to update the original code for the address’ sanitization method so that it looks like this:
Notice that the class passes an instance of itself into the validation class (which is what the interface calls for) and then will sanitize the data and return it, or will return false if the validator finds that the data isn’t ready to be saved.
This will display an error and prevent information from being written into the database.
The Cities
Just as the city validator class was similar to the address validator class, the sanitization method is going to look almost exactly the same:
On one hand, this is good because it shows that having our validation ruleset and error message handling abstracted into its own class keeps our responsibilities separate so that we’re able to focus on a single task at a time.
But on the other hand, and this is important:
We’re already seeing a violation of the DRY principle and we’re seeing what many developers would consider a code smell. Arguably, code like this should be moved into a place where it can be called so that if something changed, we only have to change it in one place.
How would we go about doing that? Were this a more advanced series, I’d likely create a base class for all of the settings, have them inherit from it, and – when necessary – keep similar validation logic in the base class that each child could call if it were a redundant piece of code.
That’s beyond the scope of this article, though. If you’re interested, leave a comment and I’ll see about expanding the series beyond what we have here; otherwise, this is sufficient for demonstrating the basic object-oriented principles within the context of the WordPress Settings API.
The Postal Codes
Recall that when we wrote the code to validate our postal codes that it was a bit more complex than other rulesets that we were writing. To that end, it might stand to reason that the sanitization method would look different, as well.
But remember, the whole point of having responsibilities encapsulated in other classes is so that third-party classes that call on them don’t have to manage that type of work. To that end, the code is actually almost exactly the same as the other classes.
Generally speaking, this is the mark of good object-oriented design. Sure, it could stand to be improved as mentioned above (and as I’ll cover more momentarily), but the general principle at work here is that the responsibilities, rules, and error message handling is managed by another class.
This means that when we need to make our rules stricter or more relaxed, we go to those classes, not the settings classes themselves.
A much easier way to manage the codebase, right?
The Best Way To Do This
So after all of these posts and all of this code, is this the best way to do? Honestly, if I were working in the context of a larger plugin, I’d probably either move the validator as a property of the class or use some form of dependency injection to add the validator to the class.
Furthermore (and as mentioned throughout this post), I’d create a base class from which all settings classes would inherit so that, when necessary, they can pass the sanitization code up to the base class so as to prevent code redundancy.
But that’s beyond the scope of what we’re doing here.
Instead, we’re focused on taking the input, handing it off to the validator, and then continuing execution and this serves that purpose well enough.
Series Posts
- Sanitizing Multiple Values with the WordPress Settings API
- Sanitizing Arrays: The WordPress Settings API
- On Pause: The WordPress Settings API
- Refactoring Input Sanitization with The WordPress Settings API
- Validating Input via the WordPress Settings API
- Validation and Sanitization in the WordPress Settings API
Leave a Reply
You must be logged in to post a comment.