Where Can I Watch? 1.4.0 is out, and it’s one of the bigger releases since launch. Two ideas drove most of the work: making Today its own top-level tab, and giving Episode Detail a consistent home in every place in the app where you might tap into an episode.
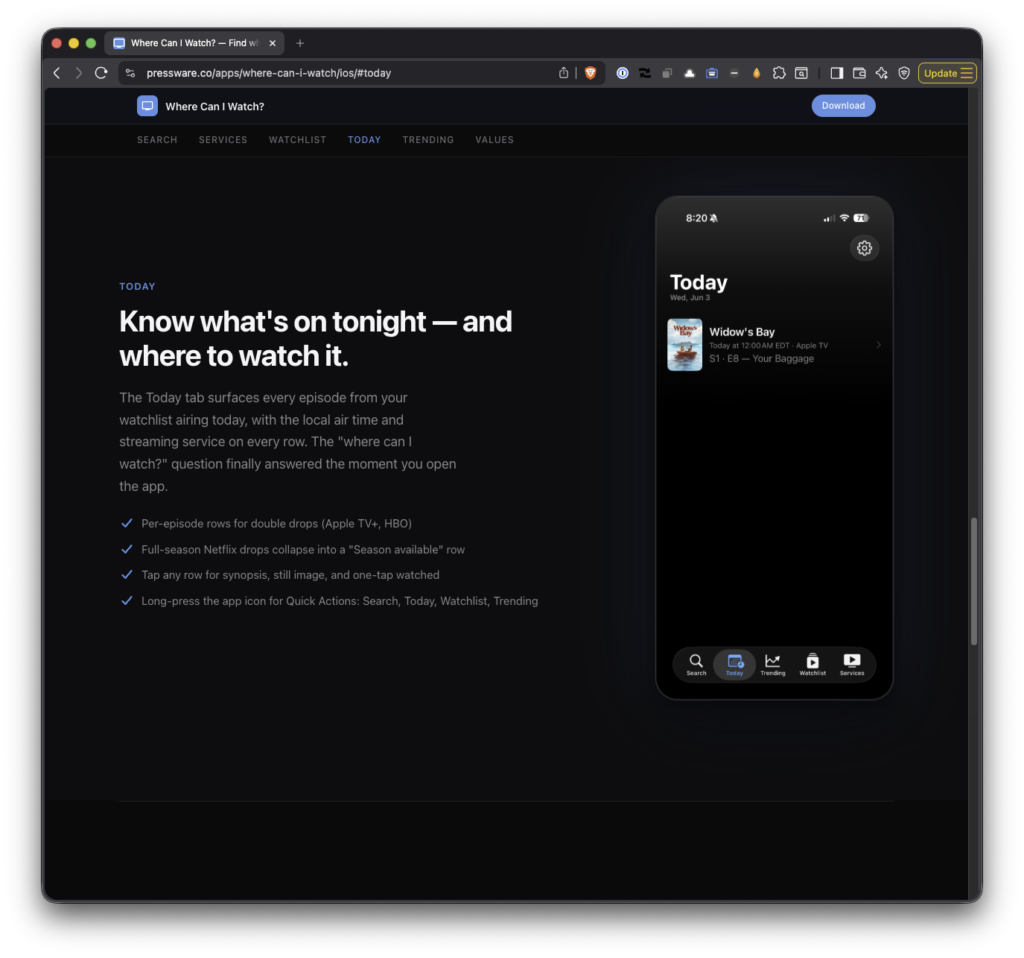
When 1.3.0 shipped, the plan I wrote for 1.4.0 was a detail-page overhaul:
- content rating badges,
- runtime,
- on-your-services callouts,
- and person search.
The more I continued to use the app, the more it was clear the foundation for those enhancements wasn’t quite in place yet:
- Episode Detail only opened from one corner of the app,
- Today was still a pinned section inside Watchlist,
- and the streaming service name, the whole point of the app, was missing from a few places a user would most want it.
1.4.0 puts those foundations in place. The detail-page enhancements will be in 1.5.0, built on top of everything in this release.
Continue reading