At some point in every developer’s career, there is going to be a time where you do something that tanks production.
- Maybe you’ll push code that ends up busting a cache that serves data to millions of people,
- Perhaps you’ll update an application and end up blowing away information that’s not backed up,
- Or maybe you’ll push a change that “works on your machine” but completely hoses the source control repository.
And there are plenty of other examples. I’m sure you can quickly name five more yourself.
I’ve committed (pun intended, sort of) my fair share of all of the above but one of the things that I see from people working in our space.
That is, those who work with database-backed web applications – is the lack of understanding of database organization at the file system level and how it is possible to reconstruct data even when you don’t have a standard backup off of which to work.
In this post, I’m going to take a deep dive into MySQL database organization at the file system level, how you can restore information from that versus a backup file should you find yourself in that situation, and provide references (or bookmarks) should you need them.
MySQL Data Reconstruction
To be clear, I’m going to be talking about a MySQL database running on a variant of a *nix-based operating system (so you’re looking at a distribution of Linux or macOS).
The locations of the files (which I’ll cover momentarily) will vary on a Windows-based system, but you’ll have to refer to the MySQL manual or a similar resource to find them.
The point is: Before going too far into this article, know where the files reside on your operating system. For example, if you’re running macOS and then you’re likely to find it in /usr/local/mysql/data.
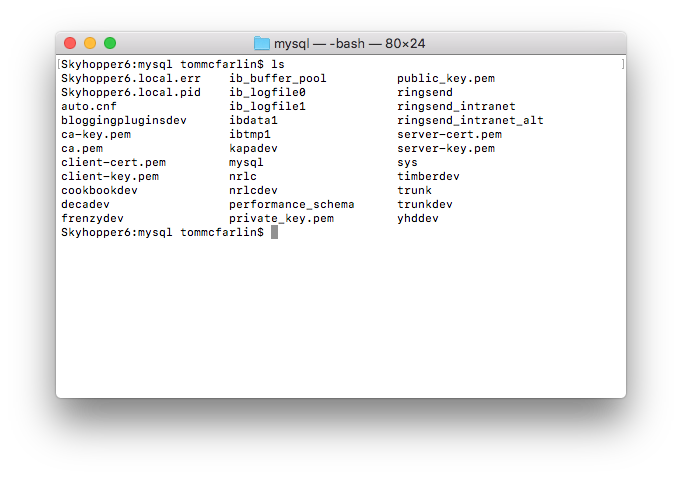
I prefer to use Homebrew so my MySQL databases are in /usr/local/var/mysql. And as you can see above, you’ll notice files that have the same name as the databases that you have on your system.
How Databases Are Organized
At the surface level, it looks pretty simple. But if you’re to open the directory as mentioned above, you’ll find that much of what you see are directories – not files, per se – that house more information.
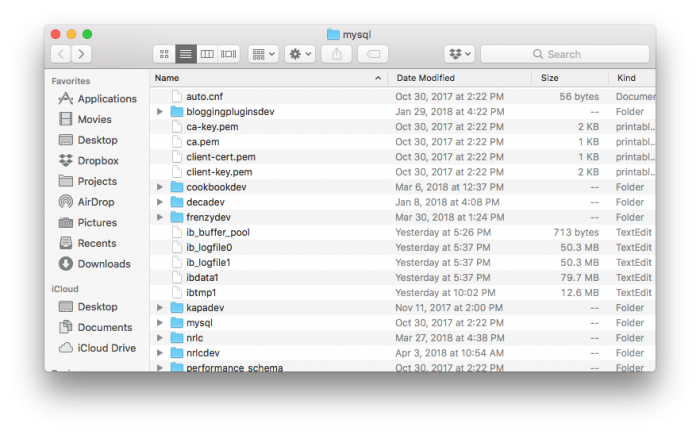
If you drill down into one of the directories, then you’re going to see a variety of files:
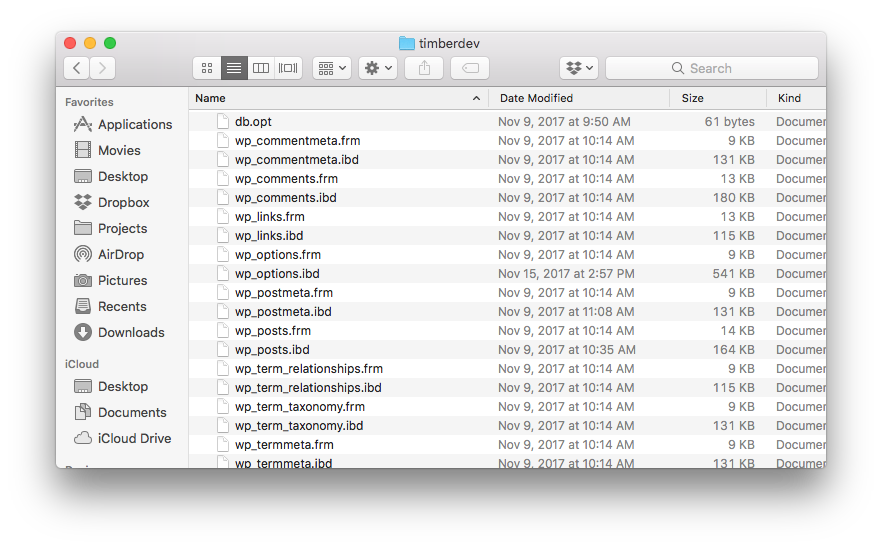
These include files that include the following types:
- MYD
- MYI
- FRM
- IBD
And each of these types of files exists for each table in the database.
So let’s look at these more in-depth to get a greater understanding of exactly what a database consists.
1. The Database Is a Set of Files
Generally speaking, most of us know that MySQL is a relational database and each database consists of a set of tables all of which store different types of information (and many tables are related to one another in some way even if it’s just a value in a single column).

But this post isn’t about the relational aspect of the database nor is it about how we’re able to run queries against it. (If you’re interested, have at it – it’s all based on tuple calculus.)
Instead, this is about understanding that for each table, there are a set of files that reference information contained in each table. And
2. Understanding the File Types
Since each table in a database is made up of the above file types, let’s look at the individual file type and then determine the role it plays for each table (and ultimately how this factors into the whole database).
- MYD. This file contains the data that’s stored in the rows of the database table. This file is closely related to the FRM file.
- FRM. This file contains the table format data (which includes things such as how each column of the database is meant to be structured, the type of data it holds, and so on).
- MYI. This is the database index. If you’re using a MyISAM database (which most of us are using InnoDB at this point), you’re going to have this file. Further, the data includes information about whether or not the data has been properly closed. Consider this to be a file on the integrity of the table itself. Not the information within it, not the format of it.
- IBD. This is a file type that’s associated with InnoDB database tables (so you may not see this in your database’s directory). If you do, however, it’s important to know that InnoDB-based databases will store information about each table in this file.
In the above information, there are two other topics worth exploring.
- MyISAM
- InnoDB
Before looking at each of these, note that MyISAM and InnoDB are what are referred to as storage engines. It sounds fancy, but it has to do with how the database software manages the operations of creating, reading, updating, and deleting information.
MyISAM & InnoDB: What’s the Difference?
Each of these storage engines differs in how they deal with transactions, locking, rollbacks, and searches. For those who are database administrators, you’re familiar with all of the above (but you’re also likely not reading this 🙃).

Not this type of engine, of course.
For the rest of us, this is what we’ve got:
- Transactions occur whenever at least two statement like SELECT and UPDATE or INSERT and DELETE or any combination of the two (or more) are used in conjunction with one another. So if you were to SELECT information and then DELETE the results, you’d have a transaction.
- MyISAM does not support transactions. This means that if a “transaction” is interrupted then, any data that was being processed during the operation is affected. Needly to say, this is not used.
- InnoDB, on the other hand, guarantees that the changes will not be made to the table until the transaction as been completed. In other words, the changes will not be committed to the database.
- For each of the storage engines, locking varies at the table level or the row level. Whenever you’re running a query against a table, MyISAM will lock the entire table until the process is completed. InnoDB, on the other, will only lock the rows that are being affected. This is an important distinction because it means you can continue to operate on a table, just not the same rows, whenever you’re using InnoDB.
- Rollbacks are not possible in MyISAM. This means that once a change is made, it’s done. InnoDB offers rollbacks. So let’s say you make a change to the table, you accidentally did something you didn’t mean to do, then you can roll it back to its previous state. This is not to be confused with a backup, though. It’s more of like an “undo” operation for a transaction.
- Searching, especially in the way we structure our databases, is key in how we organize data in our databases. Simply put, InnoDB supports FULLTEXT indexing (as of MySQL 5.6.4). But if your host or provider does not allow for FULLTEXT indexes, I would argue that it’s not a dealbreaker.
Given all of the information above, it’s each to see that the advantages of the InnoDB storage engine far outweigh those of the MyISAM storage engine especially if you’re above to use a version of MySQL that’s at least equal to 5.6.4
3. Recreating the Database
At this point, let’s assume that you know you have access to the files that make up the database from the operating system.

Perhaps it’s a previous backup, perhaps you’re able to locate the files on disk, or perhaps you’re able to retrieve them in some other way – and you need to restore the database to a previous point.
1. Don’t Do It on Production
Before doing anything, set up an empty database on your local machine and then work to import the information. But, again, this isn’t like simply using a database front-end to import an SQL file.
Instead, create a directory that matches the name of the database that you want to create. In this post, I’ll use the example of trunkdev (as this is where I do work using the most recent version from WordPress trunk).
2. Backup the Existing Database
Next, backup the existing database as much as possible – be it using a database front-end or a copy of the files. After that, copy the files from the source location into the directory that you created.
You should, at this point, be able to load up your database front-end of choice and see the information that’s contained in the database files that you just copied. This is contingent on the files not being corrupted and the database server running.
3. Do Not Install Other Software
Note that, at this point, I would not try to install other software on it like WordPress or any other information. Instead, work directly with the data. Assuming that it’s visible in your front-end, do a proper backup or export of the file into an SQL file so you can more easily restore the information in the future.
Some front-ends will give you the ability to export only certain tables. In this case, back up everything. For some databases, this will take a long time; for others, not so much. It all depends on the size of the project.
4. Work with the Data
At this point, you should be able to begin manipulating the database using the front-end or SQL. If you’re not comfortable or even sure how to do this, then talk with someone who is as this can be something that’s incredibly sensitive (after all, you’re dealing with reconstructing a database from files, right?)
Once you believe that you have the information in a place that’s ready to be restored to whatever application lost information, corrupted information, or simply has malformed data, then it’s time to prepare to take the information from your local machine and send it back to the source.
Back to the Source
First, all of the above is recommended to be done during low-traffic times so make sure that whenever you do this, you’re not going to be doing it during peak working hours. This should go without saying.
Next, take a backup of the database before you begin operating on it. Save the file in a location that you can easily recall and easily access so that if something goes wrong with using the information you’re about to import, then you’re covered and simply restore what was already there. To be clear, export the entire database in SQL format.

Now take the database that you have on your local machine and export that information into an SQL file as well. Open the exported file and make sure that it’s using a CREATE statement to create the database with the proper name and the tables with the proper names, as well.
Assuming all goes well, everything you’ve imported will be restored exactly as it should be and as you see on your local device. If you don’t see that, then import the file you exported earlier; otherwise, you’re good to go.
What If It Doesn’t Work?
If It doesn’t work, you’re going to have to get down to the root issue:
- Did it not work because of something wrong with the files from the server?
- Did it not work because of the type of database you created on your local machine?
- Are you using the same storage engine? You should be since it’s coming from the files.
- Is the integrity of the database solid locally?
- Is the database on the server being deleted before importing the data from your local machine?
If it’s not working at this point, it’s usually going to be because of something like what’s above. However, it could be something else. I’ve done what I can to provide as much information possible about MySQL databases, how they are structured, and the steps necessary to reconstruct the database from files but I can’t capture every potential edge case.
Always Backup Data (And Don’t Assume It’s Being Done)
That said, I do hope all of the information above gives a deeper understanding as to what’s laying underneath WordPress should you face this issue on your own or with a customer.
And, finally, always backup. Do manual backups, do automatic backups, and do them frequently. Don’t limit it to the database, either. Backup the database, the application, and whatever else is necessary to power the solutiokn.
If you do, then you won’t have to worry about all the above.
